

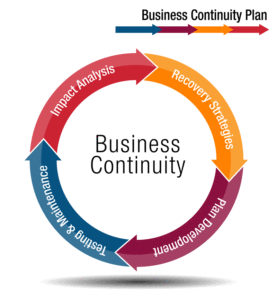
In 2010, we presented a plan to a law firm to expand its Backup and Disaster Recovery system (DR) into a Business Continuity system (BC). Disaster Recovery enables a business to resume operations after a disaster concludes; Business Continuity allows the business to operate during and after the disaster. Continue reading “By Planning Ahead, Businesses Can Survive Disasters”