

In 2010, we presented a plan to a law firm to expand its Backup and Disaster Recovery system (DR) into a Business Continuity system (BC). Disaster Recovery enables a business to resume operations after a disaster concludes; Business Continuity allows the business to operate during and after the disaster.
The DR system was built around preserving data by backing up to tape and restoring data to repaired or replaced computers. The risk is the time that might be needed to obtain replacement parts or replacement computers. The BC system would copy production data to a second location daily. In an emergency, the second location would become primary. To keep costs down, one offsite computer would contain the information processing capability of the 12 computers at the firm’s headquarters.
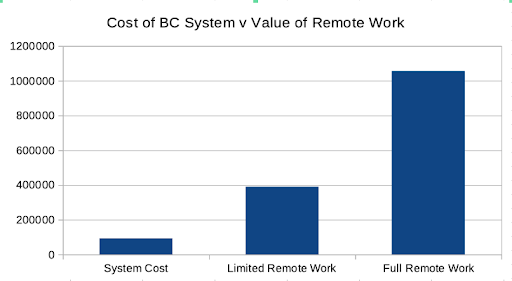
At the time, we budgeted $80,000 to implement and $6,400 per year to test and maintain the system. Unfortunately, the managing partner declined to fund the project. Two years later, when Hurricane Sandy hit, the firm was closed for one week. Had he funded the project, the attorneys who lived in areas with power and internet access would have been able to work remotely. But because the firm only had a Disaster Recovery system and not a Business Continuity plan, they were unable to work until power came back to their lower Manhattan offices. We estimate that the firm lost $390,000 to $1.1 million in revenue in the disaster.
As illustrated below, the costs of the system would have been negligible compared to the billings if some or all attorneys had been able to work remotely.
A year and a half later, in June of 2014, the firm closed its doors. The details are below, in Risk Mis-Management at a Law Firm.
We proposed a similar plan to an auto parts company with offices in New York and Connecticut. We implemented a DR & BC plan that replicates critical systems and data to the Microsoft Azure Cloud. The details are below in A Home Run in Auto Parts.
Risk Mis-Management at a Law Firm
The original Backup and DR plan at the law firm was implemented in 2006. The plan was tested in 2009, when we had to re-establish email after an incident which corrupted the email system. It took three (3) days to recover including one (1) day lost to obtaining a computer from a facility on Long Island. This illustrates that the best-case scenario for obtaining replacement servers, hard drives, or other parts is 24 hours; meaning a critical system would be unavailable for an additional 24 hours.
After the e-mail incident, we proposed using offsite backup technology to replicate the production systems, located in lower Manhattan, to the firm’s satellite office in Mineola, NY. The key benefit would be the ability to immediately transfer Information Technology operations to Mineola, if a disaster hit New York City. People would not have to go to Mineola to work. They would be able to work from home, while accessing email, the accounting system, and other critical data. Unfortunately, the firm’s managing partner did not see the need for this backup safety system.
When Hurricane Sandy hit in October, 2012, the building housing the firm’s main offices and data center lost power for a week. All 65 attorneys, including those who worked from home or in remote offices, were unable to work.
As is detailed in Table 1, below, if all 65 attorneys had been able to work from home, the firm could have billed $1.056 million during that week, over 10 times the cost of the BC system.
| Cost of Business Continuity versus the Cost of Disaster – All Attorneys Working Remotely | |||
| BC with DR | Disaster | ||
| Upfront (2010) | $80,000 | Hourly Rate | $325 |
| Testing in 2011 | $6,400 | Hours | 50 |
| Testing in 2012 | $6,400 | Attorneys | 65 |
| Total Cost | $92,800 | Total | $1,056,250 |
Even if only the 24 attorneys who routinely worked from Mineola and other remote offices had been able to work, the firm could have billed $390,000 for the week; over four times the cost of the system.
| Business Continuity versus Cost of Disaster – With 24 Attorneys Working Remotely | |||
| BC with DR | Disaster | ||
| Total Cost | $92,800 | Total | $390,000 |
| Table 2: Cost of BC v Cost of Disaster, Some Attorneys Working Remotely | |||
While we don’t know the extent, if any, that this incident influenced their thinking, in June, 2014, a year and a half after the incident, the managing partners sold the firm and closed its doors. Our final project for the firm was migrating the firm’s servers to “The Cloud” in order to allow the equity partners and their accountants to close the books properly.
Virtualization
Computer Virtualization installs the programs, storage, and processing capabilities of several computers in one powerful computer. This one computer is referred to as the “Virtualization Host” or “Host.” The individual computers in the “Host” are referred to as “Virtual Computers,” “Virtual Machines,” or “VMs.” All of the VMs in a single Host can run at the same time. Each VM has it’s own processor, memory and disk resources, and these resources of one VM are not accessible from the other VMs. Common virtualization software environments include VMware and Microsoft Hyper-V.
Without virtualization, when designing Business Continuity systems we need one spare computer for every business-critical computer. We would need one accounting server for every accounting server, one email server for every email server, and so on. With 12, 15, or 100 servers in our production environment we would need 12, 15, or 100 servers in our DR facility. In addition, we need duplicate copies of all software. We also need to duplicate our networking, power and air conditioning systems to support this environment. Then we need to copy, or replicate, the data from the production environment to the BC environment, and copy all changes on a daily basis.
In addition to paying the full price of these systems, we only plan on using them three or four days per year; when we test the Business Continuity Plan. And, of course, we need to perform other standard maintenance. As with other production systems, the best practice is to replace the systems every four (4) years.
With Virtualization, we could replicate the data processing capabilities of five or 10 individual computers in one Virtualization host. However, with virtualization in a company’s offices, we still need to invest in local, on-premises, computers, software, power, air conditioning and maintenance. This may be why the Managing Partner at the law firm decided not to spend the money on the BC system. We presented it as an investment in a fail-safe plan to manage risk; he may have seen it as wasting money in a system that he would never use.
The 2010 Plan
The 2010 plan was to duplicate the systems and data located in the data center in lower Manhattan, in a “Virtualization Host” located in the firm’s offices in Mineola, NY. The systems in the data center are illustrated in Figure 1, below. The “Virtualization Host,” is illustrated in Fig 2.
 |  |
| Fig 1: Typical Server Rack | Fig 2: Typical Virtualization Host |
Enter the Cloud
Today, we can also replace actual, physical computers with virtual machines in “The Cloud.” These Virtual Machines can be used for backup storage, disaster recovery and business continuity, or daily operations. If we are building a so-called “Private Cloud” in our own facility, then we need to buy or lease the computers and storage systems. If we are using Microsoft Azure, Amazon Web Services, AWS, or another “Public Cloud,” using the model they call “Infrastructure as a Service,” or “IaaS,” then Microsoft, Amazon, or the other service provider buy the hardware, software, power, air conditioning and other costs. We effectively rent data storage space and processing power when we need it.
Cost Comparison of DR & BC Options
| Item | Premises Based* | Cloud Based |
| Upfront Costs | $80,000 | $10,000 |
| Annual Testing | $4,000 | $4,000 |
| Annual Maintenance | $2,400 | |
| Annual Data Storage | $1,200 | |
| Annual Costs | $6,400 | $5,200 |
| Costs over 4 years | $105,600 | $30,800 |
| * Estimates from 2010. |
Both upfront costs and annual costs are significantly lower with the cloud based business continuity than they would be with premises based systems. In addition, the upfront costs for a premises based system must be incurred every four (4) years when hardware is replaced. The upfront costs for a cloud-based system are not repeated because there are no significant hardware systems that need to be replaced. The costs of Amazon Web Services, AWS, should be in line with the costs of Microsoft Azure. Please note that all environments are different. These estimates are based on the infrastructure that would support a small to mid-sized law firm or accounting firm.
Cost Comparison of DR & BC Options over Time
| Item | Premises Based* | Cloud Based |
| Costs over first 4 years | $105,600 | $30,800 |
| Costs over next 4 years | $105,600 | $25,600 |
| Total over 8 years | $211,200 | $56,400 |
| Annual Cost | $26,400 | $7,050 |
| *Estimates from 2010 |
A Home Run in Auto Parts
We also developed a Disaster Recovery & Business Continuity system for an auto body parts company. The company has a data center warehoused in the New York Metro area. Our goal was to create disaster recovery and business continuity plan that would allow the company to continue to operate even if its primary location was not accessible.
Both locations are connected to the Internet using local cable providers and to each other using a Virtual Private Network. (VPNs use encryption to simulate a private line.) New York has a virtualization host running Microsoft Hyper-V with a local ISCSI storage array. This is illustrated in Schematic 1, below.
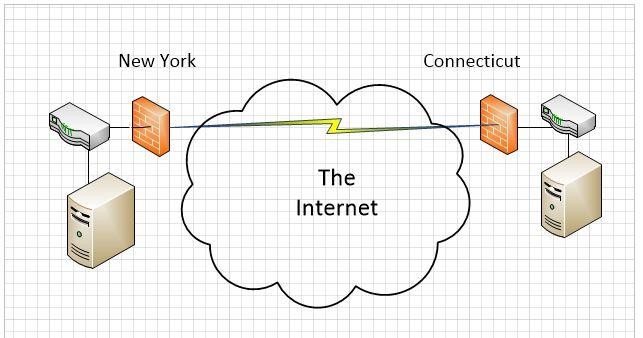
The original plan was to replicate the systems in the New York data center to Connecticut.
Strike 1: Hyper-V Replication
The systems are virtualized using Microsoft Hyper-V software. We attempted Hyper-V Replication, but that failed. Because of insufficient bandwidth from the Internet Service Providers, ISPs, data storage needs outstripped replication capacity: data were being generated faster than could be transmitted; This was “Strike 1.”
Strike 2: ISCSI Replication
As is often the case, the database servers used local disk on Network Attached Storage systems, NAS systems. These are configured using ISCSI protocols. We tried replicating the data on these disk volumes across the networks using technology built into the NAS systems. This also failed, also due to network bandwidth. Strike 2.
Home Run: Azure Site Recovery Services, Azure SRS, or Azure.
Rather than replicate the New York site to Connecticut, we configured Microsoft Azure Site Recovery Services, Azure SRS, or Azure, to replicate the production data center from New York into the Microsoft Azure cloud. As illustrated in Schematic 2, below, New York connects to Azure via the Internet, and the data are protected via VPN and firewalls.
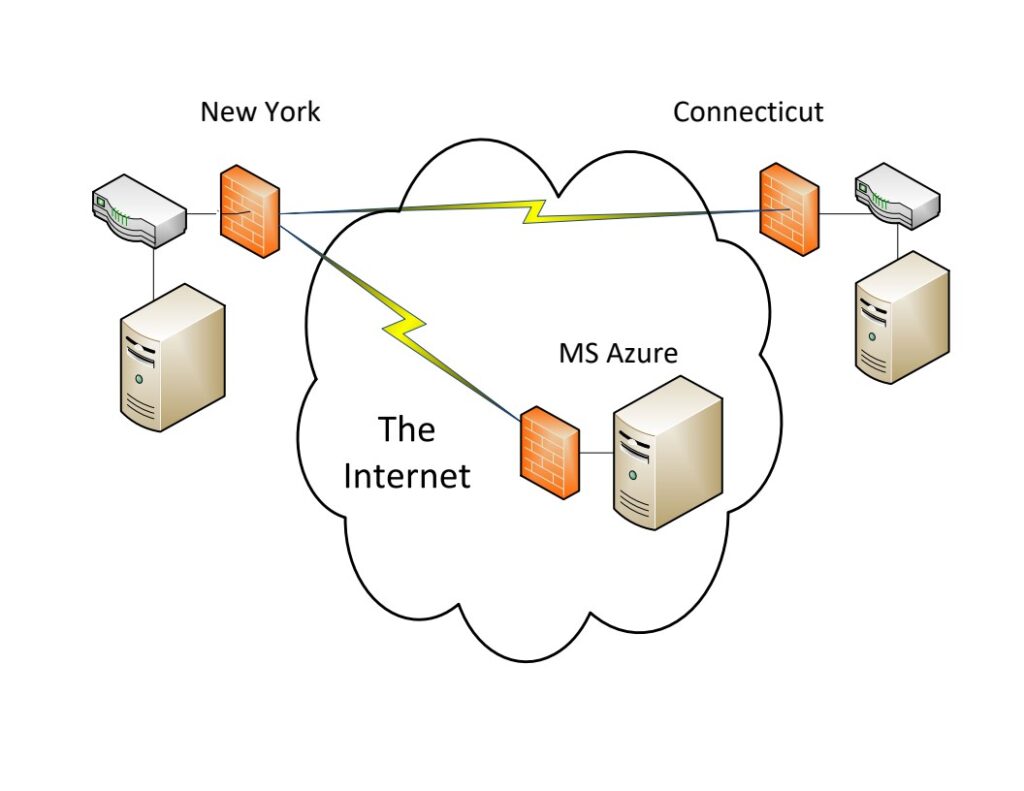
We could have used Amazon Web Services, AWS, however, Microsoft’s Azure SRS is a better choice in this case, because the systems are virtualized using Microsoft’s Hyper-V software.
It took us less than 20 hours to configure Azure SRS and prove the technology with successful tests. Thus, a “Home Run.”
What’s Next?
We have tried to present the business case for disaster recovery and business continuity using The Cloud. The next posts will discuss moving infrastructure – computer servers and data storage systems – out of premises-based data centers and into The Cloud using Microsoft Azure. Amazon Web Services, IBM Cloud, and other Cloud service offerings.
The team at ana’s cloud is available for long term and short term projects relating to disaster recovery planning, cloud migration, software development and other information technology consulting.
Appendices
Appendix 1: Project Plan: Cloud Based Disaster Recovery and Business Continuity
- Identify the systems that must be protected and available during a disaster.
- Replicate those systems to the Cloud.
- Verify data integrity: the data must be complete and correct.
- Add Data to the primary site and verify that it replicates to the DR site on schedule.
- Test “Fail Over” from Primary to Replica.
- Test Return to the Primary site. This is called “Fail Back.”
- Document the Fail Over and Return processes.
- Test Fail Over and Return on a quarterly basis.
Appendix 2: Technical Notes regarding Azure SRS Replication Methods
Azure Site Recovery Services offers different replication methods for three (3) sources of data: Physical Servers, Hyper-V Clients, and VMware Clients.
We set up replication to Azure based on their storage type of each server. As is often the case, for better performance, the SQL and ERP database servers were configured to use direct drive access. Replication on these systems requires installation and configuration of Azure SRS agent software. They are configured as if they are standalone computers, or “physical” servers, rather than “virtual” servers. The other servers use Virtual Hard Disk, or VHD storage. Hyper-V and Azure SRS connect seamlessly without the need for additional software.
Roles, Storage Type & Replication Method
| Server Role | Storage Type | Replication Method |
| Domain Controller | Hyper-V with VHD Storage | Hyper-V Replication, Azure SRS |
| Database Server, MS SQL | Hyper-V with Direct Drive Access | Physical Server, Azure SRS Agent |
| Web Server | Hyper-V with VHD Storage | Hyper-V Replication, Azure SRS |
| File Server | Hyper-V with Large VHD Storage | Hyper-V Replication, Azure SRS |
| Database Server, ERP | Hyper-V with Direct Drive Access | Physical Server, Azure SRS Agent |
Appendix 3: Technical Notes regarding Troubleshooting Replication
1. Start with the Domain Controllers, DC’s.
- Always start the fail over test of the DC. Failover is impossible if the DC does not replicate correctly and does not boot with all correct roles. Common issues include:
- SYSVOL is not created. (For more information click here for MS Support article 94722.)
- The DC is not advertising its services. For more information click here for Spiceworks article 2129243, “AD Problems, DC Not Advertising.”
2. Sufficient local storage for successful replication?
“Sufficient local storage” is a function of the amount of changes during the replication interval. For example, when replication is configured as a nightly process, and there are 250 GB of data to transmit, you need at least 250 GB of space. You should also provide a margin for extra space as data transmission may vary.
3. Sufficient Bandwidth to carry the traffic?
There are three (3) ways to resolve issues arising from low bandwidth Internet service such as from cable modems or small business class Internet.
- 1. Turn off verification during upload.
- Verification can generate so much log data and network traffic that replication will fail.
- 2. Force traffic to external connection that is less busy.
- You may need to set up a second Internet connection for each site, and force certain kinds of traffic, e.g., email, over one connection and the replication over the other.
- 3. Don’t start initial copy of all the servers simultaneously.
- Wait until a server has completed its initial replication before starting replication for the next server. Schedule daily replication to start after backups have completed.
4. VMware or Linux?
MS Azure supports VMware, and virtual machines running the Linux operating system. VMware Admin credentials are required for successful installation and execution of the AZURE SRS software. These include the Domain Administrator and VMware Linux server login IDs and Passwords.
5. Hyper-V Virtual Machines using Direct Access to local Drives?
As noted above, for reasons having to do with performance, databases are often set up with direct access to local or ISCSI disk resources. Azure SRS can’t sync VM clients with local drives using Hyper-V. You must set it up as a local physical server with the Azure SRS agent.
Morris Djavaheri, CEO of Ana’s Cloud, has over 25 years of experience in the financial industry and legal community. He has planned and executed virtualization, Disaster Recovery, Business Continuity, and agile software development projects. Morris can be reached at MorrisD@anascloud.com
Lawrence Furman, MBA, PMP, currently a Project Manager at the U. S. Dept. of Veterans Affairs, has over 25 experience in the financial industry and the public sector. He has worked on backup and disaster recovery and infrastructure projects since 1996. Larry can be reached at LarryF@anascloud.com.